Turning the Web Into EPUBs
I made a browser extension to read the web offline
Table of Contents
This mini-series is coming to a close! It started with me wanting to read articles on my Kindle but only finding mediocre browser extensions to do the job, so it will now end with a brand new web to EPUB extension by yours truly :3
Turning my blog posts into EPUBs isn’t that hard as I have access to the original markdown files. Turning any arbitrary web page into an EPUB? Now that’s a toughie. Fortunately, Mozilla open-sourced their readability library that they use for Firefox’s reader view, so I just needed to make an extension that uses this to create and download EPUBs.
Picking A Framework
JavaScript frameworks are comfy to use, and I found three for making browser extensions; thankfully someone on Reddit made this comparison chart. I wanted to develop the extension for both Chrome and Firefox, so CRXJS was out. Framework-agnosticism is something I value, but when I saw Plasmo has paid plans I crossed it off and went with WXT.
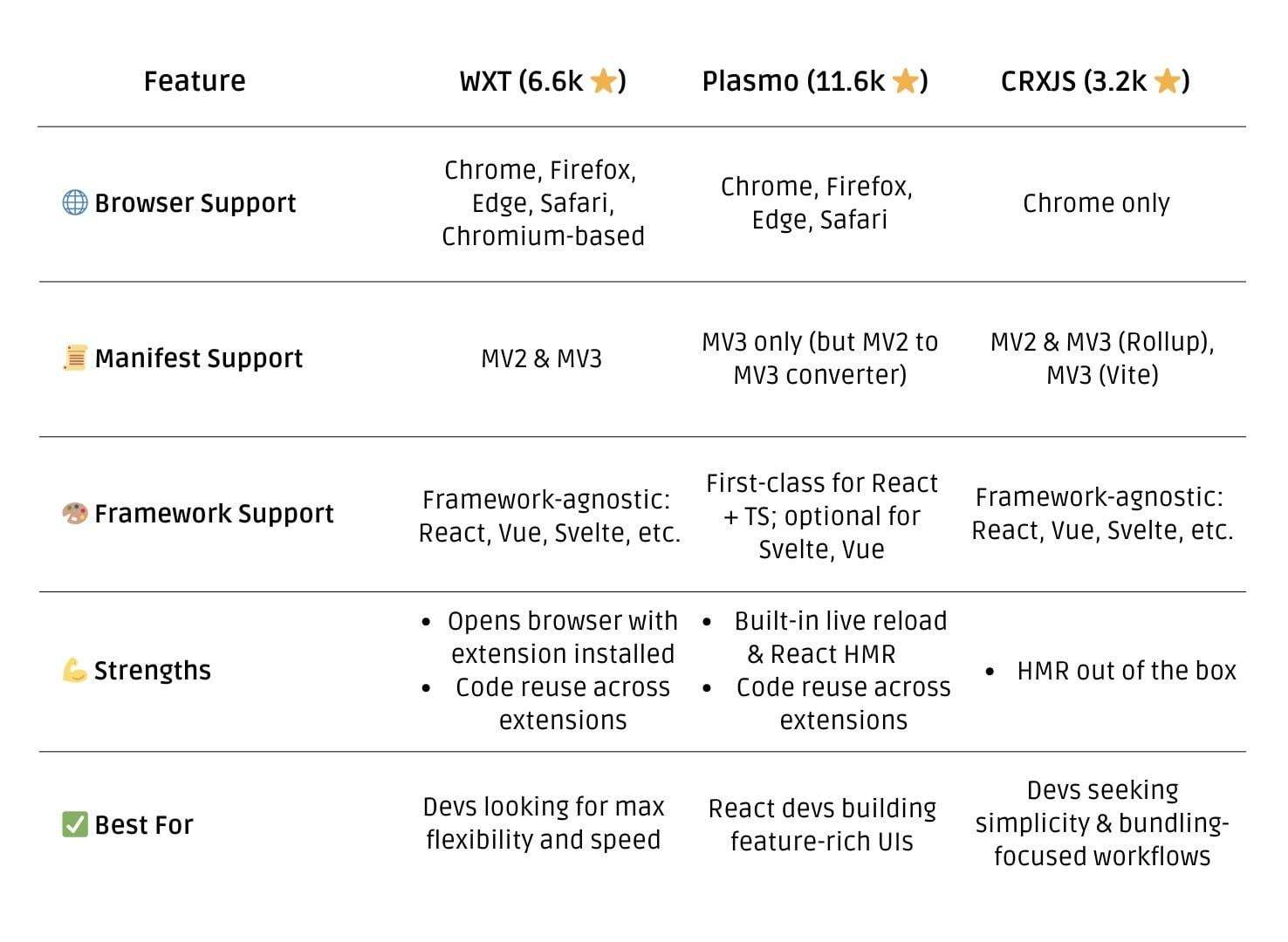
WXT has a simple bootstrap project, and the project structure feels familiar having used Next.js and Astro before; I opted for using a src/ directory as it was more like Astro. I didn’t use much of WXT’s features, but I appreciated their publishing page telling you how and where to publish to the different storefronts.
The Interesting Bits
There are 3 main kinds of scripts that browser extensions can have; the content.js script that runs directly on the page, the background.js script that runs on a hidden background page (or in the case of Chrome, it’s a web worker), and a popup.js script that runs in the popup when you click on the extension icon. These are all sandboxed into their own documents * Except for background scripts on Chrome, which have no document. , which means the popup and background scripts cannot interact with the web page.
Since the button to convert the page to an EPUB is in the popup, it needs to send a message to the content script to read the page through the readability library. Since there is only one popup script, but many content scripts, it also needs to send it to the right one.
// popups.js
browser.tabs.query({
active: true,
currentWindow: true,
}).then(tabs => browser.tabs.sendMessage(tabs[0].id, {}));
// content.js
browser.runtime.onMessage.addListener(message => {
// You need to clone the document as it will delete elements
const documentClone = document.cloneNode(true);
const article = new Readability(documentClone).parse();
// Check if article exists
if (article.content) {
alert("No article found");
return;
}
// ...
}The same steps were taken from the previous post, but using this helper function to extract the files embedded in the extension. As for images, you can’t fetch() them in the content script dues to CORS; but you can in the popup or background scripts. The sharp library unfortunately doesn’t work in the browser, so I’m extracting the images as is. * Maybe I can find other libraries that can resizes images in the browser?
async function getFile(path) {
const url = browser.runtime.getURL(path);
return (await fetch(url)).text();
}Something I learned, despite already knowing this, is that using an actual HTML parser is so much easier than writing cursed regex  I’m also making use of it’s ability to turn HTML into XHTML, as EPUBs require that.
I’m also making use of it’s ability to turn HTML into XHTML, as EPUBs require that.
// Parse HTML string
const frag = document.createRange().createContextualFragment(article.content);
// ...
// Serialize to XHTML string
const content = new XMLSerializer().serializeToString(frag);What’s super cursed about downloading files from extensions is that you can’t. At least, not normally. What you have to do is create an <a> element, turn the file into a data URL, add it to the link, and force your browser to click it. Thanks, I hate it .w.
// Download zip file
const a = document.createElement('a');
document.body.appendChild(a);
a.style.display = 'none';
const url = window.URL.createObjectURL(zipData);
a.href = url;
a.download = title + '.epub';
a.click();
window.URL.revokeObjectURL(url);Post Mortem
That’s about all the interesting things I had to say about developing a cross-browser extension! I had to make a minor update after seeing the Chrome version not working, because of how it handles things slightly differently. If you want to read the source for yourself, here ya go, and as for the downloads, here they are!
In the future I will continue to update the extension so that it provides better quality EPUBs, such as bespoke support for various websites in situations where the readability library extracts too much or too little.


{kind=link}